
Version Control
Prerequisites / recommended skill level
| Prerequisite | Importance | Notes |
|---|---|---|
| Experience with the command line | Helpful | It is possible to use version control through desktop and web browser based tools. These are discussed towards the end of this chapter, but the general principles and best practice discussed in the preceding sections are relevant regardless of whether the command line or a GUI is used. |
Recommended skill level: beginner - intermediate. Version control has a great deal of useful features, but total mastery is not necessary to achieve a great deal with it. Even a beginner utilising a few of the simplest features well can save themselves a great deal of time and drastically improve the reproducibility of their work. Naturally, we encourage readers to make use of the entire chapter, but readers should not be discouraged from using some tools they feel comfortable with if they are not comfortable with all the tools available.
Summary
Version control keeps track of different versions of a project and allows past versions to be accessed easily. It also allows different versions of a project to be merged with minimal input from the user. Version control is often associated with writing code, but it can also be used with writing projects. For example, if you are writing a paper with collaborators then version control is really important in helping you to see who has changed what. Version control is used to some extent within many different programs, including ones you are likely to already be familiar with such as Word or Wordpress. There are numerous tools available for version control such as Mercurial and SVN. The best know one is Git (and its web-based version, GitHub, which aids collaboration between researchers) which the instructions given in this chapter will be geared towards. There are a large number of detailed tutorials available online discussing the features and mechanics of how to use such systems (see the "Further reading" section at the end of the chapter). This chapter aims to cover the general principles underpinning all version control systems, and best practice which applies for using all such systems.
How version control is helpful
Researchers often have a large array of files (code, data, figures, notes) that they update but that they want to keep past versions of for reference. This process is often informal and haphazard, where multiple revisions of papers, code, and datasets are saved as duplicate copies with uninformative file names (for example, my_code.py my_code_2.py my_code_2a.py, my_code_2b.py). As authors receive new data and feedback from peers and collaborators, maintaining those versions and merging changes can result in an unmanageable proliferation of files. It is also incredibly error prone. It is easy to forget what different files contain, or to copy over files you do not mean to. This leads to a great deal of time wasted on figuring out what files contain and reproducing accidently overwritten files.
One solution to these problems would be to use a formal Version Control System (VCS). A formal version is often a better solution than the lightweight version control that is often provided by text editing software packages. These systems have long been used in the software industry to manage code. Version control allows you to revert files you select back to a previous state, revert the entire project back to a previous state, compare changes over time, see who last modified a file, find where and when a bug was introduced, and more. Using a version control system also generally means that if you screw things up or lose files, you can easily recover. In addition, you get all of this for very little overhead. Many people have felt the horror of losing days if not weeks of work when changes to a code break it irretrievably and can not be unpicked, and with this lies the key reasons to use version control: it removes risk and saves time.
Keeping past versions of a project stored and accessible makes it possible to track its entire evolution, making the outputs far more reproducible. Version control software does this in a neat and powerful way, and it often saves researchers a great deal of time on reproducing lost code or analysis. Further, version control gives researchers more freedom to try things out and experiment. It does this by eliminating the risk of subsequent changes irrevocably 'breaking' the code as previous working versions will remain accessible regardless of how complex or how many changes are made.
Another benefit of version control is that it makes collaboration easier, safer, and allows what changes have been made, when, why, and by who to be tracked. It does this by allowing different versions of a project (either two versions written by the same person, or versions from many people) to be worked on separately. It also has facilities to automatically compare and combine versions of a project, tasks which are often both fiddly and time-consuming when done manually.
Version control: What it is and how it can be used to manage an evolving project
What it is
What is "version control" and why should you care? Version control is a system that records changes to a file or set of files over time so that you can recall specific versions later. It is typically applied to managing changes in code, though in reality you can do this with nearly any type of file on a computer.
The basic workflow
The typical procedure for using version control is as follows:
- Create some files - these may be text or code.
- Work on these files, changing, deleting or adding new content.
- Create a snapshot of the work at this time. This will be described differently in different software. Git will ask you to make a commit, other systems make ask you to make a timepoint or checkpoint or just to save your work.
Keep doing work and making more and more snapshots. You can think of these as savepoints - if you need to go back to any point in time because of a mistake, or changing your mind about a decision, you can go back to get a file as it was then, or just return your entire project to a past state. An illustration of this is shown in the figure below.
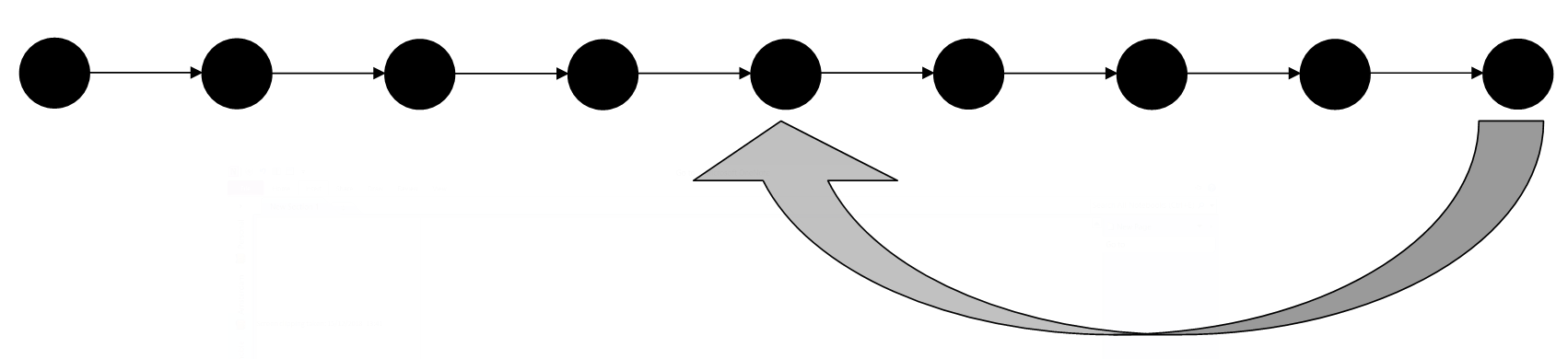
In lots of version control systems you will be able to add a comment explaining what changes have been made in this version. These comments should be as clear as possible and make it easy to understand which version is which. This ensures that it is easy to find what you are looking for when you need to go back to a past version. Your collaborators will thank you, but so will future versions of yourself.
Other facilities offered by version control
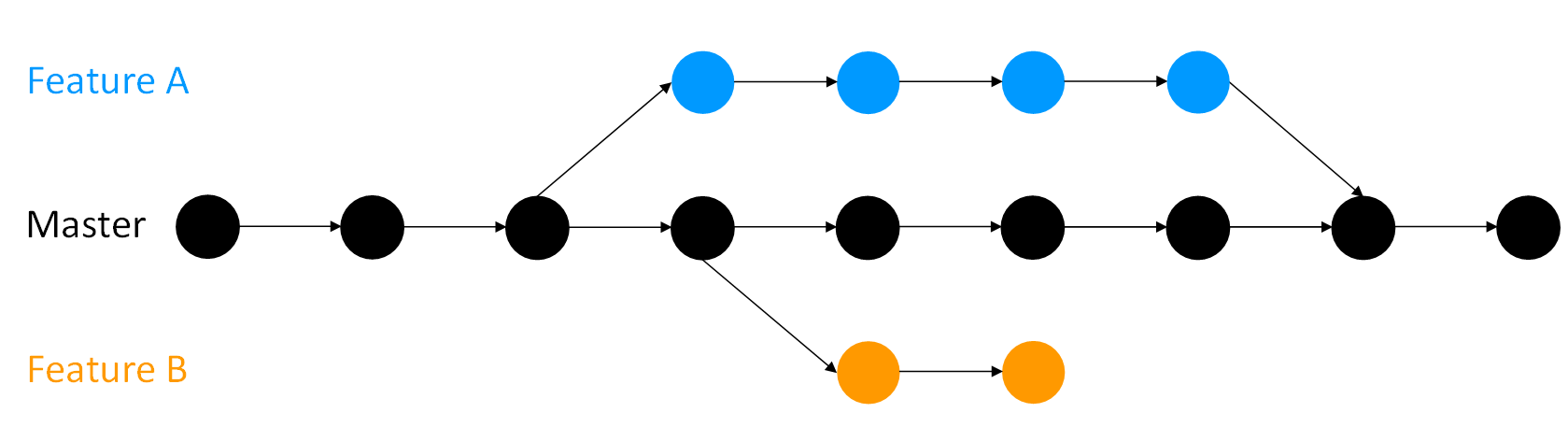
So you have your project and you want to add something new or try something out. With some of the more advanced version control systems (for example Git) you can make a branch to do this work on. Any work you do on your branch will not be present on your main project (referred to as your master branch) so it remains nice and safe and you can continue to work on it. Once you are happy with your New Thing you can 'merge' your branch back into your master copy.

You can have more than one branch off of your master copy, and if one of your branches ends up not working you can either abandon it or delete it without the master branch of your project ever being impacted.
If you want you can even have branches off of branches (and branches off of those branches and so on).
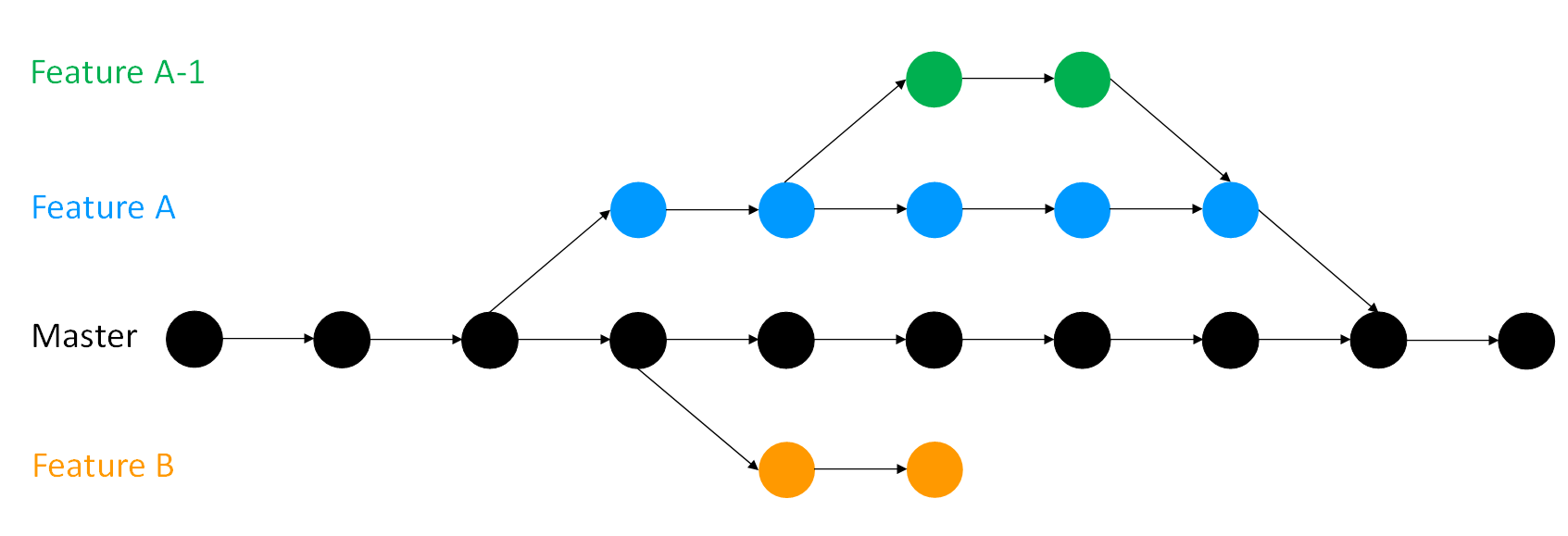
No matter how many branches you have you can access past savepoints you made on any of them.
Why should you use version control?
Version control can help you understand what changes you made in the past or why you did a certain analysis in the way you did it even weeks or months later when you have long since forgotten. By including comments and commit messages, each version can explain what changes it makes and what the version of the project it contains does. Commit messages also help others working on the same project to more easily understand what you did. This is helpful should you want to share your analysis (not only your data), and/or make it auditable -- more generally, reproducible, which is good scientific practice.
A version control system stores all your changes neatly away so while it is still easy to access them your working directory is not cluttered by the debris of versions past that it is necessary to keep just in case. Similarly with version control there is no need to leave chunks of code commented should you ever need to come back to an old version again.
Finally version control is invaluable for collaborative projects where different people work on the same code simultaneously. It allows the changes made by different people to be tracked, and can automatically combine people's work via merging saving a great deal of painstaking effort to do so manually. Moreover, version control hosting websites, such as GitHub, provide way to communicate in a more structured way, such as in code reviews, about commits and about issues.
Getting Started
This is important to know, but it is not that exciting. Instructions for installing Git on linux, windows and mac machines are available here. Once installation is complete, to start using version control for your project you just go into the directory that contains all of your files (subdirectories will be included) and run:
git initin the terminal to create the Git repository (often called "repo" for short). This only needs to be done once per project.
Think of the repository as a place where the history is being stored.
Each file in your working directory can be in one of two states: tracked or untracked by your repository.
In short, tracked files are files that Git knows about.
Untracked files are everything else — any files in your working directory that were not in your last snapshot.
When you first initialise a repository with git init all of your files will be untracked because your repository it does not have a previous snapshot yet, so it doesn't know about any of your files.
Therefore your next step is to add your files to the repository using:
git add .This puts your changes into what is called the "staging area". When you next commit any changes stored in your staging area will be recorded in your repository.
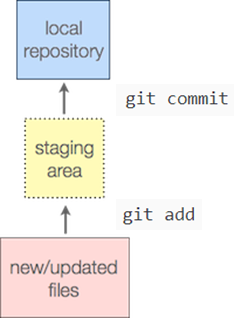
The full stop after git add above adds all changes to your staging area. So now all your files are staged commit them using:
git commitWe will talk in more detail about these commands later, but for now just know if you run them then congratulations, you have finished setting up you repository!
Commits
The problem
When working on a project you will make numerous changes to your files as you progress. Sometimes you may need to undo changes, take another look at past versions, or compare versions.
Saving each version individually (such as version_1.py and version_2.py) is messy and quickly becomes impractical.
The solution
By making commits you can save versions of your code and switch between them/compare them easily without cluttering up your directory. Commits serve as checkpoints where individual files or an entire project can be safely reverted to when necessary.
How to do it
When you have made a series of changes and you want to commit them you first add these changes to your staging area using git add.
You can add all your changes using:
git add .or you can add the changes to specific files via:
git add your_file_nameIf you are ever unsure what files have been added, what files have been changed, what files are untracked, you can run the following to find out:
git statusWhen you're ready you can commit everything in your staging area by running
git commitIt's that easy.
You can see a log of your previous commits using
git logIn this log you'll see that each commit is automatically tagged with a unique string of numbers and letters called a SHA which you can use to access and compare them.
Retrieving past versions
To cancel your latest commit run
git revert HEADwhich automatically makes a new commit that undoes those changes. You may want to retrieve a version form weeks or months ago. To do this first use git log to find the SHA of the version you want to retrieve. To reset your entire project to this version do
git checkout SHA_of_the_versionYou may just want the old version of a single file though, and not the previous version of the whole project. To retrieve this use
git checkout SHA_of_the_version -- your_file_nameGood practice
Commits should be 'atomic'. That is, they should do one simple thing and they should do it completely. For example, adding a new function or renaming a variable. If a lot of different changes to your project are all committed together then if something goes wrong it can be hard to unpick what in this set of changes if causing the problem, and undoing the whole commit may throw away valid and useful work along with the bug. That said you do not necessarily need to do per-file commits. For example if I add a figure to this chapter here, let's choose something to catch the attention of someone skimming through:

then when I do this two files are changed:
- The figure file has been added.
- I have added a reference to this figure in the chapter so it will be displayed.
So two files are affected, but "Add figure to version control chapter" is a single, atomic unit of work, so only one commit is necessary.
To aid in making atomic commits it is good practice to specify the files to be committed, that is, adding files to the staging area by name (git add your_file_name) rather than adding everything (git add .). This prevents you from unintentionally bundling different changes together, for example if you have made a change to file A while primarily working on file B you may have forgotten this when you go to commit, and with git add . file A would be brought along for the ride.
Finally, do not commit anything that can be regenerated from other things that were committed unless it is something that would take hours to regenerate. Generated files just clutter up your repository and may contain features such as timestamps that can cause annoying merge conflicts (see below). On a similar note you should not commit configuration files, specifically configuration files that might change from environment to environment. You can instruct Git to ignore certain files by creating a file called .Gitignore and including their names in it.
Commit messages
The problem
As you work on you project you will make more and more commits. Without any other information it can be hard to remember which version of your project is in which. Storing past versions is useless if you can not understand them, and figuring out what they contain by inspecting the code is frustrating and takes valuable time.
The solution
When you commit you have the chance to write a commit message describing what the commit is and what it does, and you should always, always, always do so.
A commit message gets attached to the commit so if you look back at it (for example, via git log) it will show up.
Creating insightful and descriptive commit messages is one of the best things you can do to get the most out of version control.
It lets people (and your future self when you have long since forgotten what you were doing and why) quickly understand what changes a commit contains without having to carefully read code and waste time figuring it out.
Good commit messages improve your code quality by drastically reducing its WTF/min ratio:

How to do it
When you commit via:
git commitnotice that a field appears (either within the terminal or in a text editor) where a commit message can be written. Simply do so and save (and close if writing the message via text editor). To set your preferred editor as the default do:
git config --global core.editor "your_preferred_editor"Good practice
The number one rule is: make it meaningful. A commit message like "Fixed a bug" leaves it entirely up to the person looking at the commit (again, this person may very well be you a few months in the future when you have forgotten what you were doing) to waste time figuring out what the bug was, what changes you actually made, and how they fixed it. As such a good commit message should explain what you did, why you did it, and what is impacted by the change. As with comments you should describe what the code is doing rather than the code itself. For example, it is not obvious what "Change N_sim to 10" actually does, but "Change number of simulations run by the program to 10" is clear.
Summarise the change the commit contains in the first line (50-72 characters), then leave a blank line before you continue with the body of the message. By doing this when shortened versions of git log are used just the summary will appear. This makes it much easier to quickly search through a large number of commits.
It is also a good practice to use the imperative present tense in these messages. In other words, use commands.
Instead of "I added tests for" or "Adding tests for", use "Add tests for".
Here is a good example of commit message structure:
Short (50 chars or less) summary of changes
More detailed explanatory text, if necessary. Wrap it to
about 72 characters or so. In some contexts, the first
line is treated as the subject of an email and the rest of
the text as the body. The blank line separating the
summary from the body is critical (unless you omit the body
entirely); tools like rebase can get confused if you run
the two together.
Further paragraphs come after blank lines.
- Bullet points are okay, too
- Typically a hyphen or asterisk is used for the bullet,
preceded by a single space, with blank lines in
between, but conventions vary hereComparing versions
The problem
At some point it is likely you will need/want to compare versions of a project, for example to see what version was used to generate a certain result.
The solution
In short: git diff.
Diffing is a function that takes two input data sets and outputs the changes between them.
git diff is a multi-use Git command that when executed runs a diff function on Git data sources.
These data sources can be commits, branches, files and more.
How to do it
By default git diff will show you any uncommitted changes since the last commit.
If you want to compare two specific things the syntax is:
git diff thing_a thing_bFor example if you want to compare how a file has changed between two commits use git log to get the SHAs of those commits and run:
git diff SHA_a:your_file_name SHA_b:your_file_nameOr if you wanted to compare two branches it would be:
git diff branch_name other_branch_nameGood practice
Use it.
With a little familiarity git diff becomes an extremely powerful tool you can use to track what files have changed and exactly what those changes are.
This is extremely valuable for unpicking bugs and comparing work done by different people.
Be careful to understand what exactly is being compared and where possible only compare the relevant files for what you are interested in to avoid large amounts of extraneous information.
Branches
The problem
If you add a new feature to your project you run the risk of accidentally breaking your working code as you make changes to it. This would be very bad for active users of your project, even if the only active user is you. Also version control systems are regularly used for collaboration. If everyone starts programming on top of the master branch, it will cause a lot of confusion. Some people may write faulty/buggy code or simply the kind of code/feature others may not want in the project. There needs to be a way allow new work to be done on a project whilst protecting work that has already been done.
The solution
Branches. At the start of this chapter an overview was given of the concept of branches, but let's recap. You have a project, and you make commits on it. By default you have one branch, called 'master'. Making a branch essentially makes a copy of your code which you can work on and continue to make commits to. Meanwhile your master branch is untouched by these changes, and you can continue to make commits on it too. Once you are happy with whatever you were working on on a branch you can merge it into your master branch (or indeed any other branch). Merging will be covered in the next section. If your work on a branch does not work out you can delete or abandon it (for example, Feature B in the diagram below) rather than spending time unpicking your changes if you were doing all your work on the master copy. You can have as many branches off of branches as you desire (for example, Feature A-1).
Using branches keeps working code safe, particularly in collaborations. Each contibuter can have their own branch or branches which are only merged into the main project when they are ready.
How to do it
You can create a branch and switch to it using:
git checkout -b name_of_your_new_branchTo change between branches:
git checkout name_of_the_branchthough you must commit any work you have in progress before you will be able to switch. You can see all branches of your project simply using:
git branchwhich will output a list with an asterix next to the branch you are on.
You can also use git status if you have forgotten which branch you are on.
If you decide to get rid of a branch you can delete it with:
git branch -D name_of_the_branchGood practice
Branches should be used to keep the master branch clean. That is, master should only contain work which is complete and tested and so rightfully belongs in the master version of the project. Similarly you should try to keep individual branches as clean as possible by only adding one new feature per branch, because if you are working on several features some may be finished and ready to merge into master while others are still under development. Keeping your branches clean means only making changes related to the feature on the feature's branch. Give your branches sensible names, "new_feature" is all well and good until you start developing a newer feature on another branch.
Merging
The problem
Once you've finished up some work on a branch you need to integrate it to your main project (or any other branch).
The solution
Merge the branch with your work on into your target branch. You can also use merging to combine work that other people have done with your own and vice versa.
How to do it
To merge some branch, branch_A, into another branch, branch_B, switch to branch_A via git checkout branch_A and merge it into branch_B by:
git merge branch_BMerging will not be possible if there are changes in either your working directory or staging area that could be written over by the files that you are merging in. If this happens, there are no merge conflicts in individual files. You need to commit or stash the files it lists and then try again. The error messages are as follows:
error: Entry 'your_file_name' not uptodate. Cannot merge. (Changes in working directory)or
error: Entry 'your_file_name' would be overwritten by merge. Cannot merge. (Changes in staging area)Good practice
First and foremost your master branch should always be stable, only merge work that is finished and tested into it. If your project is collaborative then it is a good idea to merge changes that others make into you own work frequently. If you do not it is very easy for merge conflicts to arise (next section). Similarly, share your own changes with your collaborators often.
Merge conflicts
The problem
When changes to made to the same file on different branches sometimes those changes may be incompatible. This most commonly occurs in collaborative projects, but it happens in solo projects too. Let's say there's a project and it contains a file with this line of code:
print('hello world')Lets say one person, on their branch, decides to pep it up a bit and changes this line to:
print('hello world!!!')while someone else on another branch instead decides to change print('hello world') to:
print('Hello World')They continue doing work on their respective branches and eventually decide to merge. Their version control software then goes through and combines their changes into a single version of the file, but when it gets to the hello world statement it doesn't know which version to use. This is a merge conflict: incompatible changes have been made to the same file.
The solution
When a merge conflict arises it will be flagged during the merge process. Within the files with conflicts the incompatible changes will be marked so you can fix them:
<<<<<<< HEAD
print('hello world!!!')
=======
print('Hello World')
>>>>>>> master<<<<<<<: Indicates the start of the lines that had a merge conflict.
The first set of lines are the lines from the file that you were trying to merge the changes into.
=======: Indicates the break point used for comparison.
Breaks up changes that user has committed (above) to changes coming from merge (below) to visually see the differences.
>>>>>>>: Indicates the end of the lines that had a merge conflict.
How to do it
You resolve a conflict by editing the file to manually merge the parts of the file that Git had trouble merging.
This may mean discarding either your changes or someone else's or doing a mix of the two.
You will also need to delete the <<<<<<<, =======, and >>>>>>> in the file.
So in this project the users may decide in favour of one hello world over another, or they may decide to replace the conflict with:
print('Hello World!!!')Once you have fixed the conflicts commit the new version.
You have now resolved the conflict.
If, during the process, you need a reminder of which files the conflicts are in you can use git status to find out.
If you find there are particularly nasty conflicts and you want to abort the merge you can using:
git merge --abortGood practice
Before you start trying to resolve conflicts make sure you fully understand the changes and how they are incompatible. If you do not you risk making things more tangled. Once you do and you go about fixing the problem be careful, but do not be afraid; the whole point of version control is your past versions are all safe. Nevertheless merge conflicts can be intimidating to resolve, especially if you are merging branches that diverged a great many commits ago which may now have many incompatibilities. This is why it is good practice to merge other's changes into your work frequently.
There are tools available to assist in resolving merge conflicts, some are free, some are not. Find and familiarise yourself with one that works for you. Commonly used merge tools include KDiff3, Beyond Compare, Meld, and P4Merge. To set a tool as your default do:
git config --global merge.tool name_of_the_tooland launch it with:
git mergetoolFundamentally the best way to deal with merge conflicts is to, so far as is possible, ensure they do not happen in the first place. You can improve your odds on this by keeping branches clean and focused on a single issue, and involving as few files as possible. Before merging make sure you know what's in both branches, and if you are not the only one that has worked on the branches then keep the lines of communication open so you are all aware of what the others are doing.
GitHub
The problem
When multiple people work on the same project (which is becoming more and more common as research becomes increasingly collaborative) it becomes difficult to keep track of what changes have been made and by who. It is also often difficult and time-consuming to manually incorporate the different participant's work into a whole even if all of their changes are compatible.
The solution
Hosting the project on a distributed version control system such as GitHub. Collaborators can then clone the project and work on the cloned copy making commits and new branches without impacting the original repository. Collaborators can then push their work to each other, and pull other's work into their own copy. In this way it is easy to keep everyone up to date and to track what has been done and by who. GitHub also has numerous other handy features such as the ability to raise and assign issues, discuss the project via comments, and review each other's changes.
Making the entire project and its history available online in this was also has two major benefits for research:
- Other researchers can re-use the work more easily. Rather than writing their own code to do what has already been written they can just use the original, which saves time. This also benefits the project's original authors as other researchers are much more likely to build on the work (and cite it) if a great deal of the work has already been done.
- The research will be much more reproducible if the entire history of the project can be tracked. This enables results to be verified more easily, which benefits science.
How to do it
There are a number of GitHub tutorials available such as this one, or if you prefer you can follow along here.
First make an account on GitHub, and create a repository on it.
To do this click the + sign dropdown menu in the upper right hand of the screen.
Enter a name for the repository (ideally the same name as the project folder on your computer) and click Create Repository.
Now you just need to link the project on your computer to this online repository.
If your project is not already version controlled then make it so by running git init and making a commit.
In the terminal on your computer use:
git remote add origin https://GitHub.com/your_username/repository_namethen push all the files on your computer to the online version so they match via:
git push -u origin masterYou can the go on and make more commits on your computer. When you want to push them to your online version similarly you do:
git push origin branch_you_want_to_push_toOthers can then clone the repository to their computer by using:
git clone https://GitHub.com/your_username/repository_name.GitThey can make and commit changes to the code without impacting the original, and push their changes to their online GitHub account using:
git push -u origin masterNaturally the exact same procedure applies to you if you want to clone someone else's repository.
Pull requests
So everyone's got a copy of the code and they're merrily working away on it, how do collaborators share their work? Pull requests. A pull request is a request for a person to pull someone else's changes into their version on the project. Say person A has made changes they want to share with person B. On GitHub Person A needs to go to person B's copy of the project and click the "New pull request" button. From there they can indicate which of their branches they would like person B to pull changes from, and which branch they want the changes pulled to. If person B accepts then person A's changes will be merged into their repository by GitHub. They can discuss the request in comments, and make further commits to the request before it is accepted if necessary.
When person B is setting up the pull request GitHub will automatically check whether there would be any merge conflicts if they accept, and highlight them if there are. These can then be resolved in further commits before the request is accepted, keeping the merge clean and painless.
Once the request is accepted GitHub will merge person A's changes into person B's online copy of the repository. Person B can the pull those changes down to the copy on their computer using:
git pull origin masterIt is also possible to make pull requests via the command line. A guide on how to do so is available here.
Good practice
In your GitHub repository you should include a license to allow others to re-use your work legally. GitHub makes this very easy, simply click the "Create new file" button, name it "License.md" and a drop down menu will appear offering you a selection to choose from. The legalese can seem intimidating however the software licenses section offers high level overview of the different license types.
You should also include a readme file where you include useful information about what the project is, how to use it and how to contribute to it. Switching between projects in your work is common, let alone that you might need to poke at your own previous projects from time to time. This information will also assist you collaborators, and your future employer might want to check your existing GitHub projects.
There are plenty of readme templates available online, pick one you like, but here is a list of the main things a readme should include:
- The project name and what it is: This will greatly help the random prospective contributor to get an idea of the project. Include a few key points that describe the main features of the project and what are the main features you are implementing. This helps to quickly compare other projects with yours and to give an idea that why the project exists in the first place.
- Instructions on how to install the project: The installer might be a collaborator, someone that comes across and is interested in the project, or even you if you get a new machine and need to re-install your project. Nevertheless, it's a total waste of both of your resources to start figuring out how to just get started with the project. This should also include any prerequisites that will be needed to run the project. The best thing you can do is to just write up the installation instructions when you first do them yourself, and you will quickly save hours of work in the future.
- Instructions for how to run the project and any associated tests: If you have been working on your project it may seem obvious how to run it, but this will likely not be the case for someone coming across it for the first time.
- Links to related material.
- List of authors/contributors to the project, possibly with contact information.
- Acknowledgements.
It can be a good idea to include documents outlining a code of conduct, agreed ways of working, and contributing guidelines, though depending on the level of detail you want to provide the latter two can also work as sections within the readme. These documents make explicit expectations for those working on/contributing to the project, making life easier for everyone. Similarly depending on the scope of your project you may wish to provide templates for how contributors should make pull requests or raise issues.
You can also make use of one of GitHub's major features- issues. Anyone can raise an issue with the project and discuss it. By making issues for any significant changes a record can be kept of the history of the project. GitHub has a myriad of other features such a milestones and project boards which may also be of use.
In pull requests you should clearly explain what the changes you've made are and why you made them. If your changes address and issue that has been raised reference it directly. If your request fixes and issue and you include "will fix #the_issue_number >" in the pull request, if the pull request is merged it will automatically close the referenced issue, keeping the issue queue nice and clean! This also works for using commit messages to close issues too.
Summary of key Git commands
| Command | Use |
|---|---|
| git init | Initialises a Git repository in that directory |
| git add . | Add all changes to the staging area to be committed |
| git add file_name | Add changes to the specified file to the staging area to be committed |
| git commit | Commits staged changes and allows you to write a commit message |
| git checkout SHA | Check out past commit with the given SHA |
| git checkout SHA -- file_name | Check out past version of a file from the commit with the given SHA |
| git checkout -b branch_name | Create and switch to a new branch |
| git checkout branch_name | Switch to a specified branch |
| git merge branch_name | Merge the branch you are on into the specified branch |
| git clone url | Makes a clone of the repository at the specified url |
| git remote add origin url | Links local repository and repository at the specified url |
| git push origin branch_name | Push local changes to the specified branch of the online repository |
| git pull origin branch_name | Pull changes to online repository into local repository |
| git log | Output a log of past commits with their commit messages |
| git status | Output status including what branch you're on & what changes are staged |
| git diff | Output difference between working directory and most recent commit |
| git diff thing_a thing_b | Output difference between two things, such as commits and branches |
Checklists
Make use of Git
- [ ] Make your project version controlled by initialising a Git repository in its directory using
git init. - [ ] Add and commit all your files to the repository using
git add .thengit commit. - [ ] Continue to add and commit changes as your project progresses. Stage the changes in specific files to be committed with
git add filename, and add messages to your commits.- [ ] Each commit should make one simple change.
- [ ] No generated files committed.
- [ ] Commit messages are meaningful, with a ~50 character summary at the top.
- [ ] Commit messages are in the present tense and imperative.
- [ ] Develop new features on their own branches, which you can create via
git checkout -b branch_nameand switch between viagit checkout branch_name.- [ ] Branches have informative names.
- [ ] Master branch is kept clean.
- [ ] Each branch has a single purpose and only changes related to that purpose are made on it.
- [ ] Once features are complete merge their branches into the master branch by switching to the feature branch and running
git merge master.- [ ] Merge other's changes into your work frequently.
- [ ] When dealing with merge conflicts make sure you fully understand both versions before trying to resolve them.
Put your project on GitHub
- [ ] Create a GitHub account.
- [ ] Create a repository on GitHub with the same name as your project.
- [ ] Attach your local and online repositories via
git remote add origin repository_url. - [ ] Put the files in your local version of the project online via
git push -u origin master. - [ ] Continue to push changes you make on your computer to the GitHub version via
git push origin branch_name. - [ ] Pull any changes made on GitHub to your local version via
git pull origin branch_name. - [ ] Include a license.
- [ ] Include a readme.
- [ ] Set expectations for how collaborators are expected to behave via a code of conduct and or ways of working document.
- [ ] Use issues to track and discuss modifications to the project.
Contribute to someone else's project
- [ ] Clone their project's repository from GitHub
git clone repository_url. - [ ] Make and commit changes.
- [ ] Push your changes to you GitHub version of the project.
- [ ] Make use of issues to discuss possible changes to a project.
- [ ] Make pull requests on GitHub to share your work.
- [ ] Clearly explain the changes you've made and why in your pull request.
What to learn next
Look into best practice for writing good quality code (for example, good naming conventions, informative comments, modular code structure). Many such skills are either also applicable for using version control well, for example, for writing good commit messages, or make using version control easier by keeping changes neat and localised.
Further reading
- A free and very in depth book on Git's myriad of features can be found here.
- A useful Git cheat sheet can be found here.
- Interactive tutorials for familiarising yourself with GitHub can be found at https://lab.github.com/.
Definitions/glossary
- Add: Command used to add files to the staging area. Allows the user to specify which files or directories to include in the next commit.
- Branch: A parallel version of a repository. Although it is contained within the same repository it allows you to develop it separately and then merge changes back into the 'live' repository or with other branches when appropriate.
- Checkout: Git command to switch to a specific file, branch, or commit. Allows you to activate older versions of files or commits or switch between active branches.
- Clone: Copy of an existing Git repository, normally from some remote location to your local environment. When you clone a repo you copy its entire history as well as all branches.
- Commit: Snapshot of project history. A commit can be made after changes of a single file or a range of files and directories.
- Commit message: A message the user can attach to a commit to explain what it contains.
- Git: Version control system that GitHub is built around. It is a widely used open source distributed version control system developed by the author of Linux.
- GitHub: An online hosting and version control service which centres around the version control software Git. It has a great many features to aid collaboration between users.
- HEAD: the latest commit on the branch which is currently checked out
- Issues: Bug tracking system for GitHub. Collaborators can use issues to report bugs, request features, or set milestones for projects. Issues are tracked, reported, and closed by collaborators during the development process. They’re a great way of communicating with your team and reporting progress.
- Master: the repository’s main branch. Depending on the work flow it is the one people work on or the one where the integration happens.
- Merge: The process of combining branches. Changes made on one or more branches are applied to another.
- Merge conflict: Incompatibilities between branches being merged.
- Pull request: Proposed changes to a remote repository. Collaborators without write access can send a pull request to the administrator with the changes they've made to the repo. The administrator can then approve and merge or reject the changes to the main repository. For open source projects pull requests can be sent by anyone that has forked a project.
- Push: Sending changes to a remote repo. The remote repository is updated with the changes pushed and now mirrors the local repo.
- Repository: Refers to a project folder that is being tracked by Git and containing project files. Also called 'repo' for short they can be local as well as hosted on GitHub.
- SHA: Unique string of numbers of letters used to identify every commit or node in the repository.
- Staged: Changes that will be included in the next commit.
Bibliography
- 1. Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License
- 2. Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0) Other useful stuff in this paper, could use their into as part of the book's intro
- 3. Permission to use given by the author (Peter Reimann) 15/12/18
- 4. Permission given by the author (Tony Yu) 15/12/18
- 5. Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
- 6. creative commons Attribution-NonCommercial-ShareAlike 4.0 International
- 7. Creative Commons Attribution 2.5 Australia License.
- 8. Creative Commons Attribution-ShareAlike 3.0 Generic
- 9. Creative Commons Attribution 4.0 International License
- 10. Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License
- 11. Creative Commons license
- 12. GNU GENERAL PUBLIC LICENSE Version 3
- 13. "You are granted a limited license to copy anything from this site"
- 14. creative commons Attribution-NonCommercial-ShareAlike 4.0 International
- 15. Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)
- 16. Attribution 3.0 Unported (CC BY 3.0)
- 17. Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)
- 18. Creative Commons Attribution-NonCommercial 2.5 License
- 19. MIT
- 20. GNU Free Documentation License
- 21. Creative Commons Attribution-ShareAlike 4.0 International License
- 22. Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)
{kind=link}